


做过 hive 数仓的同学都知道 mapjoin 在解决大表 join 小表的时候效率极高,通常都是作为必须进行的优化手段,而 hive 也是默认开启了 mapjoin
0: jdbc:hive2://localhost:10000/default> set hive.auto.convert.join;
+------------------------------+
| set |
+------------------------------+
| hive.auto.convert.join=true |
+------------------------------+
1 row selected (0.042 seconds)
那么 mapjoin 真的是一劳永逸吗?在什么情况下 mapjoin 不仅不会提高任务效率而且还会极度的拖慢任务进程。下面是我前几天生产中遇到的问题并进行一个抽象,hive 中有一个千万级的维表和一个数据量极小的主表,当业务需求是:保留主表数据尽可能的去关联维表数据,显然是一个简单的 sql
select mobile
from (
select 938 as user_id
) t1 left join (
select *
from dim_hz_uc.user_mobile_bind
) t2 on t1.user_id = t2.user_id;
这种情况下和下面的 sql 执行效率应该差不了多少
select mobile from dim_hz_uc.user_mobile_bind where user_id = 938
但实际情况是该任务执行了十几分钟依然没有完成,通过观察日志可以发现
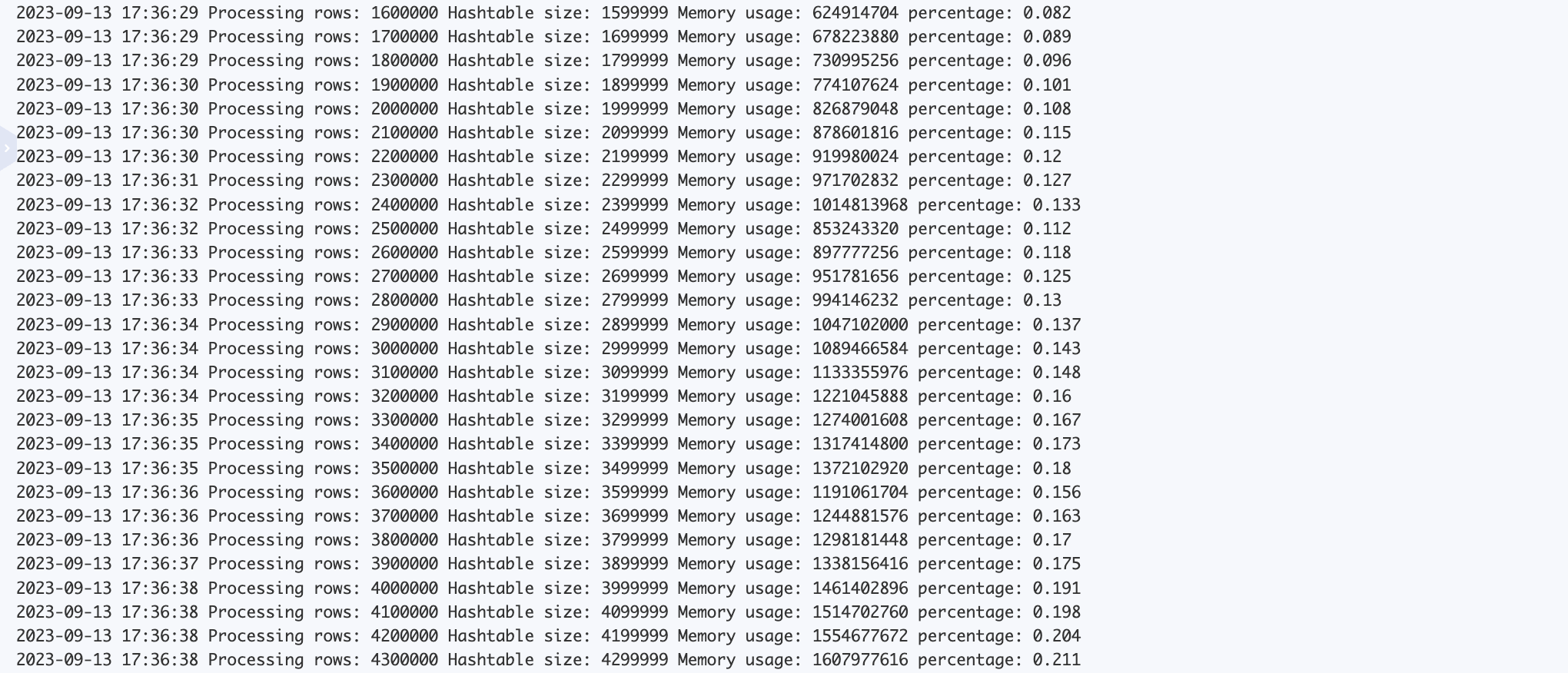
看懂上面的日志需要有一定的调优经验,Hashtable + Memory 显然是在做本地缓存,进一步分析执行计划
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
t2:yjy_user_mobile_bind
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
t2:user_mobile_bind
TableScan
alias: user_mobile_bind
filterExpr: (inc_day = '20230912') (type: boolean)
Statistics: Num rows: 4825134 Data size: 521114520 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: mobile (type: string), user_id (type: bigint)
outputColumnNames: _col11, _col9
Statistics: Num rows: 4825134 Data size: 521114520 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 UDFToLong(938) (type: bigint)
1 _col9 (type: bigint)
发现进行本地缓存的竟然是大表,多少有点不符合常理。
其实我们在理解 mapjoin 的优化方式的时候很容易忽略一个 mapjoin 的使用前提,那就是:mapjoin 只能在 inner join 中生效,具体分析可以移步至《Hive 执行计划那些事》,因为 hive 默认开启了 mapjoin,根据 mapjoin 的执行方式只能去缓存大表,这就导致大量的时间耗费在缓存上且内存使用率激增。针对这种情况解决方案其实很简单,只需要关闭 mapjoin 即可
set hive.auto.convert.join=false;
本文在分享这个案例的同时亦在传达一个观点:调优需要结合场景,一切脱离具体应用场景的调优都是纸上谈兵。在大多数场景下的优化手段在特定场景可能是导致任务失败的罪魁祸首
评论区